Taking on a BIG Storage Challenge
As IT Manager of Nebraska Global (including Don’t Panic Labs), I – along with Ted Larsen who is the other half of our entire IT department – face unique technology challenges every day. Sometimes they’re relatively simple, like recovering data after a hard drive failure. Sometimes they require a fair amount of physical agility, like pulling network cable around a 100+ year-old building. And yet other times, a bit of creativity and analysis are required to help the companies we support make the best decisions with startup-level budgets.
One of our recent challenges involved determining the best method of storing recorded data for Ocuvera, one of our companies.
Ocuvera – meeting unique challenges of their own – is addressing the issue of patient injuries caused by falls in health care facilities. They are creating and refining ground-breaking and highly complex algorithms that analyze live 3D depth data in order to predict when a fall may occur. This isn’t like finding a body’s shape for a video game. These systems are analyzing the movement and behavior of patients who are in hospital beds, under sheets, in the dark, and are oftentimes mobility challenged.
In order to test these algorithms, the Ocuvera team must study how human bodies typically move in these settings. The only way to accurately do this is to capture depth data from care facilities and “train” their systems on what to look for (and what to ignore).
This is where the need for massive amounts of data storage comes in.
Scoping the Challenge
For several months Ocuvera’s storage requirements had been on the radar. We were able to initially fulfill their needs with some hardware we already had on hand. A traditional solution made up of RAID cards and 6-terabyte drives allowed us to provide approximately 85 terabytes of storage. This was enough to survive the initial wave of data they had collected, but it wasn’t going to be enough. Ocuvera was predicting they were soon going to be bringing in terabytes of data per week.
We were obviously going to have to make an investment in hardware, but we needed to be smart about several factors. Cost of course was a huge concern. Expandability and flexibility of design were also very important, as it was hard to know how the storage requirements might change as the product progressed. Simplicity is something we value in IT here at Nebraska Global, as we have to wear a lot of hats.
The other considerations that play into a decision like this were the performance and uptime requirements of the workload. At this point, we were only asking the server to be a file server. We were not asking it to do anything highly intensive like process data or run SQL databases. We were also willing to live with small amounts of downtime, so there was not a requirement for 100% uptime.
Our Options
With cost being a definite factor, we pretty much knew we would be building our own custom solution; no pre built devices from 3rd party vendors. Not burdened with a 100% uptime requirement, we did not need a cluster. So we began weighing our single-server solution options.
To protect the data against hard drive failures, the options were to stick with more RAID cards, or move to a storage virtualization solution like Microsoft Storage Spaces. We had no prior experience with Storage Spaces as it is a relatively new technology. But being a Microsoft shop that is always looking to embrace the latest technology, we were excited to evaluate it as a possible solution.
Storage Spaces is, in a sense, software RAID in that it offers redundancy capabilities that equate to the familiar RAID1/RAID10/RAID5/RAID6 technologies. To fully define Storage Spaces as merely software RAID is overly simplistic as its capabilities go much further, and its performance is much higher than traditional software RAID offerings from Microsoft. I won’t go into the full extent of these features here, but Microsoft’s FAQ for Storage Spaces has some great detail.
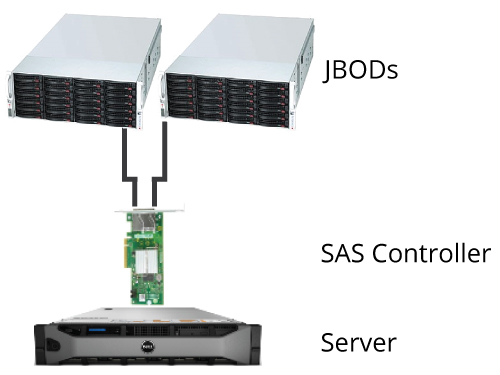
After some research and testing, we came up with a specific design that utilized Storage Spaces. This configuration included an older generation Dell server, an external 24-bay JBOD (aka Just a Bunch of Disks) from AIC, a SAS controller card from LSI, and 24 6-terabyte SATA drives from Western Digital. With this configuration, we were able to quickly deploy a 107-terabyte, dual-parity (similar to RAID6) virtual disk.

Why this configuration made sense for us can be illustrated by examining it around the factors that were previously mentioned as being important to us.
Performance and Cost
If our performance requirements were higher, a RAID card might have made sense. Because Storage Spaces is software based, it’s relying on the main CPU to calculate redundancy. Since we had plenty of free CPU with our current workload, we figured we might as well put it to use. When it comes to licensing, Storage Spaces does not require anything above the Windows OS. So by removing the expense of a RAID card we were able to maximize our cost savings.
Expandability
Expandability of our system is not something that is magically achieved through Storage Spaces or another cutting edge approach. It is achieved simply by the use of SAS and its inherent expansion capabilities. That being said, it’s still interesting to show how this can be put to use to achieve our goals. In fact, it’s something we already have put to use.
Not long after deploying our initial configuration, we connected another JBOD with 24 hard drives to our configuration and doubled our capacity to 214 terabytes. In the future we can expand further by cascading more JBODs or adding another SAS controller card to the server. How far we can take this will be driven by performance requirements and possibly the limitations of other hardware components, but the ease at which we can quickly add a lot of available storage is a huge benefit.
Flexibility
The design also allows for great flexibility. If demands would ever change and we need more performance from the system, we can simply move the JBODs to a more powerful server. We could mix and match with that approach as well. For example, we could set up some virtual disks to run more performant while leaving others alone. In that case we could connect JBODs with the appropriate servers to adjust to the necessary requirements. We are not tied to any specific controller card to do this, we simply need to be able to present the drives to the OS using a SAS connection.
Simplicity
We were definitely able to reduce complexity over the long term by going with Storage Spaces. All of our setup and monitoring is done using native Windows Server tools. There is no need for separate management and monitoring apps for the RAID card, and we are not tied to any specific RAID card vendor or model.
Recovery scenarios are easier as well. As long as the Windows OS can see the disks over a SAS connection, we can connect these disks to any server we want. No need to keep an extra RAID card of the exact same model on hand.
Final Thoughts
To this point we are more than happy with our design. The ease of deployment was awesome. While there has also been a definite cost savings to our approach, the biggest benefit we see going forward is the flexibility. It’s easy for us to see multiple upgrade paths under changing requirements. Simply put, we achieved high storage capacity at a low price point while not locking ourselves into a configuration that could possibly limit us in the future. This is one less thing to worry about as we continue to tackle the challenges of our massive data processing requirements.
But storage is just one of the challenges we’ve faced in meeting the extremely heavy hardware needs of a company like Ocuvera. We’re still in the midst of figuring some things out. In the future I will be writing on how we’ve dealt with finding the best way to increase parallel computing and the resulting need for high network throughput.