Azure Vision: Who Didn’t Make Coffee?
At Don’t Panic Labs, I get to see many business deals that come through. Over the years, they seem to have increased in complexity. Probably the most obvious way they have grown is in the number of pieces. It isn’t uncommon for a solution to have many subsystems, be hosted in the cloud, have many users, and maybe even include an IoT component.
This number of pieces creates a lot of complexity. But there is another way incoming projects have increased in complexity: we are often asked to build richer components within the applications.
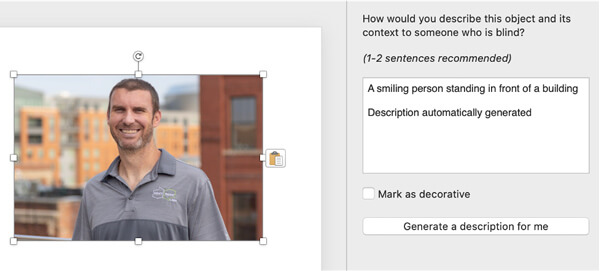
Think of Microsoft PowerPoint. If you add an image to PowerPoint, a description to go with the image is automatically generated. It is those kinds of little features that people expect in applications, additions that make for a richer experience.
The nice thing is there are some excellent solutions out there for adding these kinds of rich features – and you don’t have to be a computer vision expert to consume them.
- OpenCV
- AWS Rekognition
- Azure Vision
I often like to have some sort of fun project that forces me to learn something new. In this case, I wondered if I could use computer vision to determine who didn’t refill the coffee pot at the office.
This concept of software telling me who didn’t make the coffee reminds me of those old Terrible Terry Tate videos where someone didn’t make the coffee and Terry would tackle them.
I don’t think I need the tackle option.
We could log who last interacted with the coffee maker. Something like:
- 10:20 am Bill
- 10:21 am Doug
- 10:30 am Chad
- 10:45 am Hadley
We could do this using Azure Vision.
Like we would with any computer vision solution, we begin with some sample images of Don’t Panic Labs employees who might use the coffee maker. Then we train our system using those images.
After the system is trained, it should be able to identify the faces in the captured images.
Let’s walk through some code.
We are going to do a little set up.
- NuGet: https://www.nuget.org/packages/Microsoft.Azure.CognitiveServices.Vision.Face
- Azure API Key (Azure Face)
- .NET Console App
To train our recognizer, we need to do four things with Azure Vision.
- Create PersonGroup
- Create PersonGroupPerson
- Add image to PersonGroupPerson
- Train PersonGroup
After we have the code to train our face identifier, we can now use it to find employees in images and see if it matches.
Finding an employee in an image can be done in three steps.
- Detect Face
- Identify Person
- Compare with known people

With that little bit of code, Azure Vision can identify that the picture on the top left (Doug) matches our PersonGroupPerson for Doug. The picture on the bottom left (Bill) matches Bill.
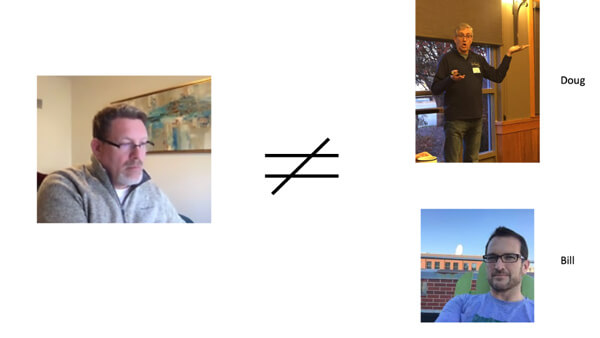
I was also able to test it to ensure that Bob does not equal Doug or Bill.
Probably one of the coolest parts of creating this demo was that I could finally get an answer to what Doug has believed for a long time: does he look like Richard Gere.
And the answer is….