

Locking in JavaScript, Just Like C#
Recently, I ran into an issue with loading data from a JSON file that was supposed to be generated through a separate process. If that process failed, I wanted to create a temporary fallback mechanism that would get the same data loaded.
The problem was that the data in the JSON file was supposed to be used on every UI page, so a lot of instances may ask for the non-existing data at the same time and need to use the fallback. Just making API calls would be way too expensive in this case. I knew that C# has the simple lock syntax that allows synchronized resource access (The lock statement – synchronize access to shared resources – C# reference | Microsoft Learn), which is what I wanted. But how do you achieve locking in JavaScript?
It turns out there are at least two ways to accomplish this.
- Via Promises – A promise is a proxy for a value not necessarily known when the promise is created. It allows you to associate handlers with an asynchronous action’s eventual success value or failure reason. This lets asynchronous methods return values like synchronous methods: instead of immediately returning the final value, the asynchronous method returns a promise to supply the value at some point in the future.
- Via Mutex – A mutex (short for Mutual Exclusion) is a synchronization primitive used in programming to protect shared data from being accessed by multiple threads simultaneously. This helps prevent race conditions, which can lead to unpredictable behavior and incorrect results (Mutex in C++ – GeeksforGeeks).
By default, promises run without disregard for what else is running out there, so…
This runs like any normal promise, but when we care about the data, we may find differences depending on when we access it.
Output for:
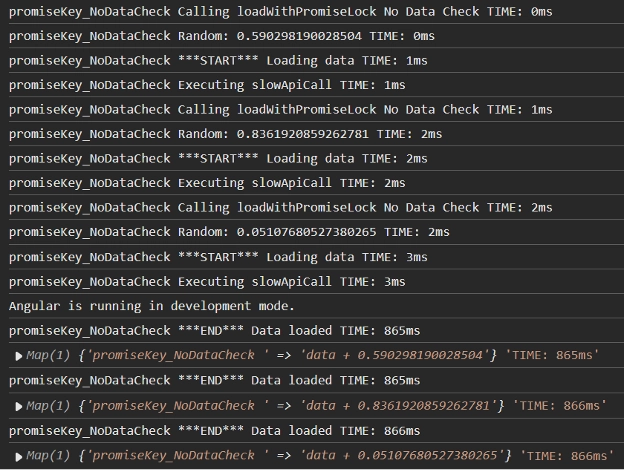
So, this is not good when we know that we want the same data but may have different origins/times.
You can adjust this so that each time you call a promise for the same data (key), you can make sure that only one of those promises is instantiated. But if someone else tries to execute the same function, you just return the promise of the first execution, so they all get the same resolved promise value at the same time.
Calling it with:
This would result in:
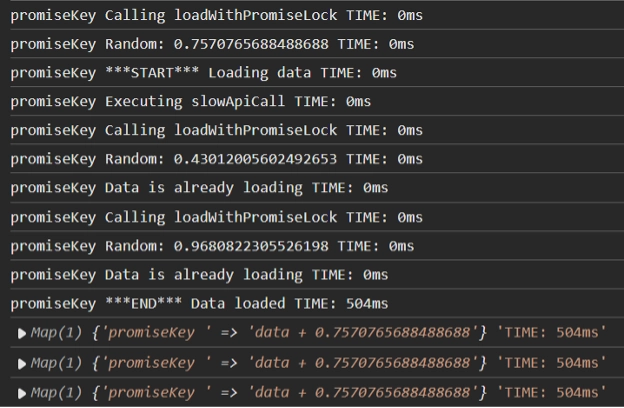
Much better. The value is predictably the same, and we only called the SlowApiCall once, so we gained some performance. Nice!
We have something functional now, but we also need to maintain the promises that we have created. It’s not difficult yet, but why try to reinvent the wheel? Mutex already handles this for us.
The equivalent implementation of loadWithPromiseLock with mutex looks like this (You will need async-mutex – npm to run this code):
It is much simpler, but with one caveat: We have to specifically make sure that we skip calls we already have data for:
The mutex will wait until the previous execution has been completed, and at that point we may have data, so we need to check for that.
Running the mutex code:
This yields:
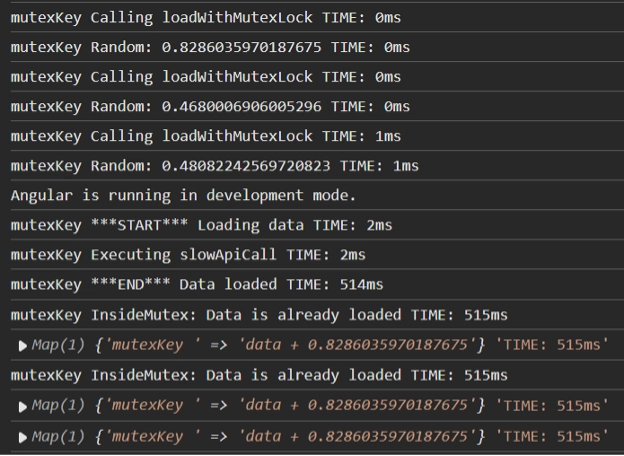
Note that two of the mutex calls were returned early because the data had already been loaded.
At this point I want to pose a question: Which one is more effective when 1000 calls happen for the same call at the same time? For example, when a page needs to get the English text for each element on the screen.
The mutex will build a FIFO queue of 1000 entries, and after the first one executes, all of the other mutex entries will follow suit and all shortcut because the data already exists.
In contrast, the promise version will only add one entry to its queue. When it completes, all callers will get the same result.
So…what did we learn?
You can apply locks in JavaScript and use either a promise (more maintenance) or a mutex (built-in maintenance).
Be careful. JavaScript is intended to be threadless, so the locking mechanism from above is a tool at your disposal but ask yourself if that is really the right solution first.
PS: For completeness, running the mutex without the data check (equivalent to loadWithPromiseLockNoDataCheck) is the simplest of implementations:
And this:
Results in:
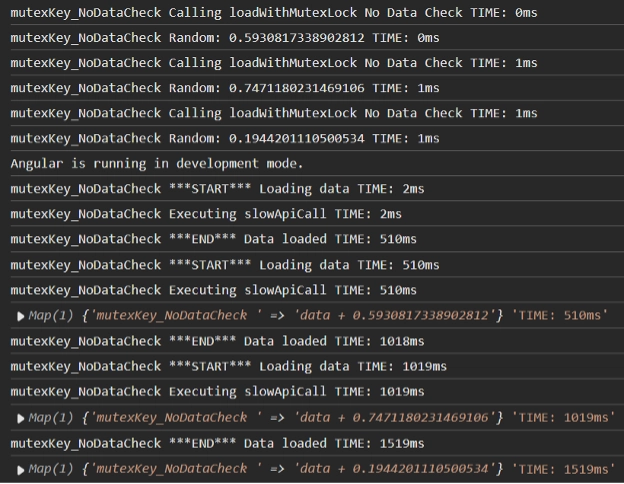
This is predictable as each call is executed sequentially, and we have 3x slowApiCall again.





