

Searching Word and PDF Documents with Elasticsearch and Apache Tika
Having the ability to search through a folder of documents, particularly Microsoft Word and PDF files, can be an excellent feature to build into systems. But how do you go about this? Which technologies can one use to bring this to life without a ton of effort?
Based on my experience, leveraging a combination of Elasticsearch and Apache Tika is a quick and easy way to add powerful file search to your application. Elasticsearch is an open-source search and analytics engine that can process nearly all kinds of data. Apache Tika is an open-source toolkit that detects and extracts metadata and text from numerous file types.
I should note that while my goal here is to search Word and PDF files, Elasticsearch and Tika can be used to search a wide variety of data.
First, let’s begin by creating a new project in Visual Studio (or JetBrains Rider, in my example below).
Next, we need to add NuGet references to Tika so it can extract the contents of our documents.

After that, we need to add NuGet references to NEST/Elastic. NEST is a high-level SDK for interacting with Elasticsearch that we will use to help perform our searches.
![]()
Now it’s time to index the documents. The code below assumes you have a directory of documents you want to search.
We need to search the documents.
Now let’s run the solution. You should see it index the documents at the location you specified.

Now we can enter our search term and get the results.
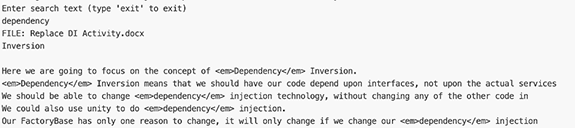
We now have a functioning document search system that can scan all of our Word and PDF files within a specific directory.
Here’s a GitHub link for the entire project if you want to try this out on your own: https://github.com/chadmichel/DocumentSearch



