

MemoryStream Limits: Handling Large Files in Azure with Blob Storage Streaming
We recently deployed a new feature to a website running in Azure App Services to combine multiple files uploaded by users into a single large ZIP file. After deploying to production, we started seeing “Out of Memory” exceptions for one of our users.
Our first instinct was that our smaller front-end web servers didn’t have enough memory. Digging into the problem revealed an exception from the MemoryStream object being used.
- at System.IO.MemoryStream.set_Capacity(Int32 value)
- at System.IO.MemoryStream.EnsureCapacity(Int32 value)
- at System.IO.MemoryStream.Write(Byte[] buffer, Int32 offset, Int32 count)
- at System.IO.Stream.InternalCopyTo(Stream destination, Int32 bufferSize)
- at System.IO.Stream.CopyTo(Stream destination)”
We determined that our problem stemmed from our building of ZIP files in a MemoryStream. Since the internal capacity of MemoryStream in .NET is an Int32, our large file sizes were exceeding the limit. Our team had to come up with a different solution for handling these rare large file uploads because there is no option in the framework to instantiate a MemoryStream with 64-bit of capacity.
Here is some example code you can run in a .NET Framework console app if you want to see the exception.
Hosting in the cloud means we have access to better tools to handle files we are managing. Since we now know that a few of our users will be uploading files much larger than we anticipated, we reconfigured how uploaded files are managed within our system. Our standard practice now has us creating large files in Azure blob storage instead of in-memory or on the local disk.
In the following code examples, I will show you how to use the CloudBlockBlob library to directly stream a large file into blob storage.
Streaming to Azure Blob Storage
Let’s swap out the MemoryStream object for a generic stream object from CloudBlockBlob.OpenWrite(). The documentation can be found here.
First, we need to create a new storage account to save our file stream to.
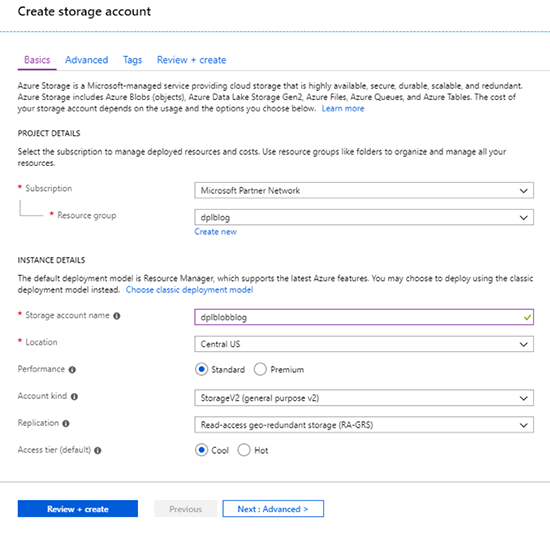
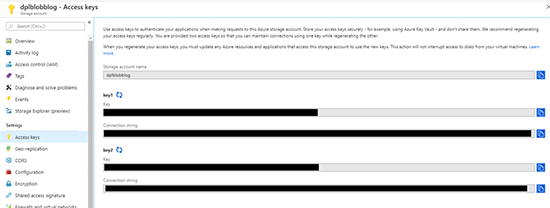
Once the resource is created, go to the Access keys blade and copy the connection string for key1.
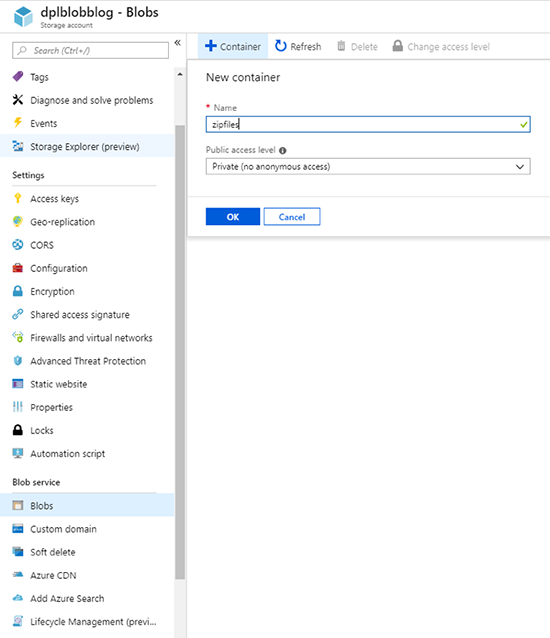
The last step in the Azure portal is to open the Blobs blade and create a new container.
Now we can change our code to use the Microsoft.Azure.Storage.Blob NuGet package to stream our new file directly into blob storage.
Warning: Running this code is going to generate a 2 GB file in the doc storage container. This may take a few minutes depending on the speed of your Internet connection.
Back to the Azure portal. There should now be a 2 GB file in the ZIP files container.
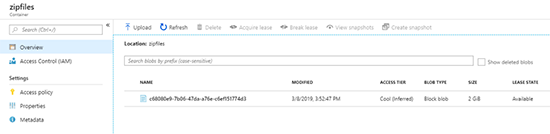
Optionally, OpenWrite() provides AccessCondition, BlobRequestOptions, and OperationContext as parameters in the constructor to configure your blob stream.
Here is an example of changing the default retry policy to linear instead of exponential. The default policy is recommended for most scenarios.
Streaming ZIP file creation with SharpZipLib
CloudBlockBlob.OpenWrite() returns a .NET Stream object which allows us to use it with other libraries that accept a stream. Our original goal was to create large ZIP files, so one last modification to the sample code to use SharpZipLib allows us to generate a 2 GB ZIP file directly into blob storage.
Wrapping Up
By avoiding using local disk or memory on our cloud servers, we can handle files of any size with less worry about scalability of our resources and the dreaded Int32 overflow. I would recommend to anyone working in Azure to handle all file creation using a stream from the CloudBlockBlob object.
If you have any questions or comments, leave them in the comments below. Or you can hit me up on Twitter where I’m @unter.



