Silly Arguments – Squash Merge Versus No-Squash Merge
Previously in this series, we discussed the silly argument of tabs versus spaces. Now we are moving on to squash merge versus no squash merge. Before getting into this topic, we should cover branching in Git.
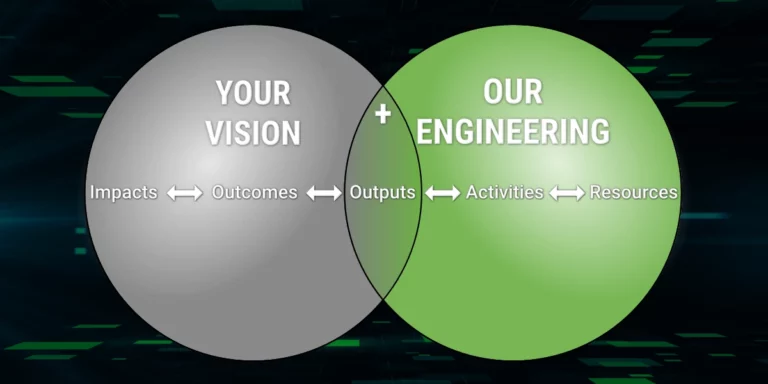
Git is a source control system created by Linus Torvalds. One of its key differentiators is that branching actually works. One of the key reason branching works is that you can merge branches back together with minimal effort.
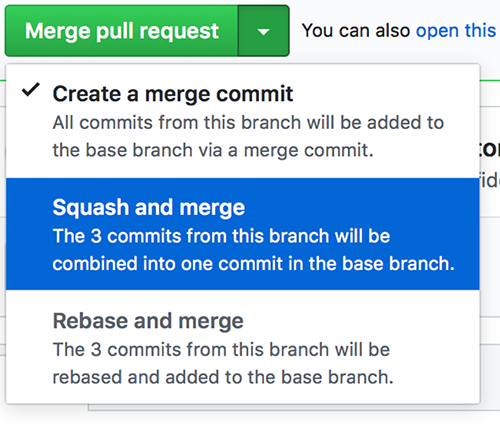
What is squash merging, and what does it mean to no-squash? Typically, when you merge two branches in Git the full history of both branches is maintained. This means every commit you make along the way is preserved. With a squash merge strategy, only one commit is merged into the destination branch and it is merged as though all the work in the source branch was done in a single commit.
Why do people not like the squash? First, some people don’t like a messy history. For me, I don’t mind it; a clean history means nothing to me. I am fully accepting of a messy history because it’s essentially a document of what happened. I don’t want a revisionist history, I want the truth.
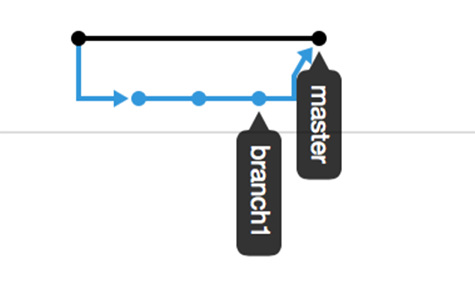
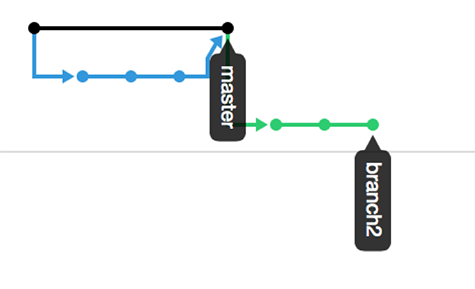
Why do people like the squash? It creates a cleaner history. If it takes you 50 commits for you to get a final good commit, many people want to remove those messy 50 commits. It hides all the mess. And GitHub supports this with a single button click.
Squash versus no-squash is another one of those areas in software development that doesn’t have a right or wrong answer; just differences in taste. I think it is good to continually review the different philosophies and keep an open mind to other options. But as with most of these, choosing one option won’t cause a drastic problem on your project.