Automating Releases
Engineers want to see their code used. Time spent on a release is time not spent working on other products or new features. Building a system that allows for automating releases can be a great way for dynamic teams to save time and focus on their passions. On the Beehive Industries team (the one on which I spend most of my time) we have done just that. Whereas my team and I used to be at the office until midnight or later, now we are able to update our customers in minutes and virtually on a dynamic schedule.
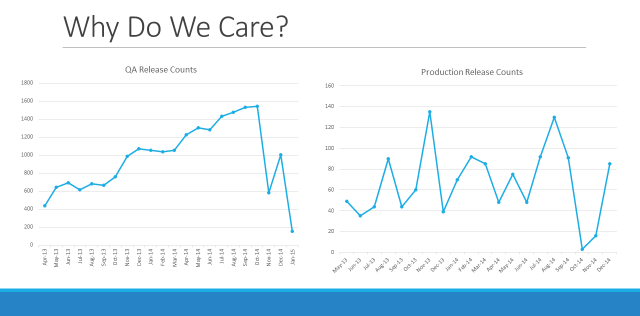
Automating releases is about more than simply saving time. It is also about creating an environment that believes in the team process. That means it is important to make something:
- Reliable
- Repeatable
- Visible
- Efficient
- Automated
At Nebraska Global and Don’t Panic Labs, this is a critical component of what we do. It is emphasized all the way from the top. In a recent speech Doug Durham, the Chief Architect and CTO of many of NG’s companies and systems said, “Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live.” This means that we have to strongly consider not just what we are doing but also the context for how and why this code will live beyond our reach.
As such, automated releases force both that level of responsibility to quality and documentation, but also to ensure that we as engineers are heavily vested in making sure the code can live beyond us and without many touches. Once that commitment is made, automating the process for releases can become a goal.
Automation of our releases is one way that we have streamlined our processes to ensure that they are able to be efficient. When we consider our release process, there are numerous variables that need to be accounted for:
- Multiple clients (websites and desktop application)
- Different customers (end users) have different versions of the software
- Each customer has its own database
- Lots of geospatial queries and indexing are required
- Multiple versions – due to new features and our constantly improving framework
These variables make the process of pushing out a new update complicated and preclude us from being able to use many of the deployment tools on the market. We made sure that we had the most effective team software for our process and all the moving pieces of our solution, which ultimately caused us to move from TFS to GIT and TeamCity. Incorporated with that move, we have built a number of internal systems to handle database continuous integration for local development as well as in our QA and production environments. Building off the engine used to handle versioning and running the database scripts, we have slowly automated the entire process of releasing a customer. All the way from taking a database backup before an upgrade to copying new services to the server.
This has allowed us to do a number of positive things regarding our release processes:
- Our release candidate builds now happen nightly (or as a simple button click by an engineer)
- Using a backup of each customer database from production, we restore and upgrade each customer’s database and application version nightly in the QA environment with the new release (ensuring a vibrant and fairly synchronous QA environment and multiple trial runs of the upgrade before it reaches production)
- We merge new features once a week
- Release to production happens weekly (based on a fairly open-ended engineer driven process)
In my job, many people ask “how” we did this. How did we shift? We did three smart things:
- We took the long road regarding the process – focusing on understanding our environment and the pain points from the beginning and working towards the goal of full automation. This meant that we were manual for a while and had frequent releases. Both of these were intended to force us to get better. It forced us to work more in sync with QA and to move QA closer to production.
- We focused on quick wins regarding outcomes rather than over-complicating the entire system. This meant that we were able to chop off about 80% of any given issue in a relatively short period of time (80/20 rule). This is a key process I’ve learned from working with start-ups – we don’t have to solve every problem and be perfect from the get-go. Instead, we want to be quick and nimble so that we can adapt to the ever-changing environment around us. Thus, we can get products to our customers really fast and solve most of their problems. Then we can evolve (and continue to do so) based on use, feedback, and actual breakage.
- Let engineers be engineers. Rather than trying to overlay a sales process or another maximization strategy, we focused on knowing our own culture and expertise. In doing so, we realized what we value: small near-time QA team, good project management that is dynamic, strong communication environment and tools, and other intangibles that we deemed critical to the process but also important to the engineering culture. We build great things – but we need the time, tools, and support of management.
In conclusion, we have built a good system that has been very valuable to Beehive Industries, and as a best practice environment for all of the Nebraska Global/Don’t Panic Labs companies.