Using Lucene.NET for Searching PDFs
Note: This post was co-authored by Emily Douglas.
For one of our recent projects, we developed a public-facing website that needed the ability to search through a large number of archived PDFs. This may sound trivial, but we had some unique needs and situations we had to work around (isn’t that always how it is):
- We had to search not only for the file name, but also the contents of each PDF
- We had thousands of PDFs and we needed the search to be fast
- The end-user sees these PDFs as belonging to different groups (committees, to be specific) but Azure blob storage keeps them in a single container
First, we figured out how to search through all the data in an Azure blob container. We followed the example in this blog post for using Lucene with Azure: https://msdn.microsoft.com/en-us/magazine/hh235069.aspx. It uses blob storage to house the PDFs and the index. Here’s how we did the rest of it.
Manually Creating Indexes
Creating an index is crucial. The process we used very closely mirrored the above blog post. We iterate over each file in blob storage and pull out the applicable data: URI, Title, Body. Since the URI is unique, it will be stored as our index key. The Body is the data of which we’re searching through. Populating the Body will be discussed later.

As you can see, Lucene takes care of a lot of the magic for us. We simply provide the data we want to search through, as well as a unique key and a storage location for the index. This got more complicated as we applied it to our project, but initial assumptions proved valid.
Searching
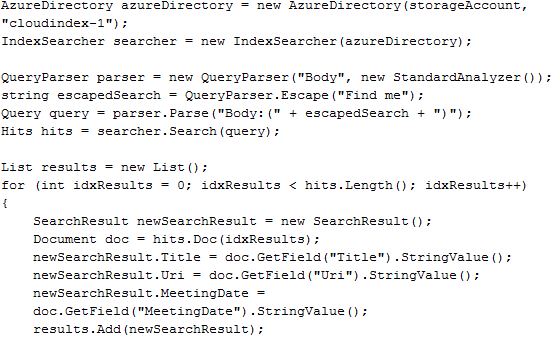
Searching with Lucene is easy. You create an AzureDirectory object as before, but this time you open it with an IndexSearcher. Then, create a query stating what data to search through and what text to search for. In the example below, we are searching through the Body, but you can search through any tokenized data you have stored in the index. The Hits object lists the results, sorted by relevance. The Document object contains all of the information previously added to the index.
PDF Parsing
Retrieving the text from PDFs posed a problem of its own. There are several free third-party libraries for creating PDFs, but very few for extracting text from PDFs. We tried PdfSharp, but most of our PDFs parsed as only new lines and it wasn’t easy to figure out how to fix it. We settled on the .NET version of PdfBox since it worked and the code was very straightforward. It is slow, but since it is run by the indexer it doesn’t impact search times.
PdfBox was written in Java then compiled to DLLs using IKVM. The only reason this matters is because you need to include these IKVM DLLs so you can access Java objects:
- IKVM.OpenJDK.Core
- IKVM.OpenJDK.Swing.AWT
- IKVM.OpenJDK.Text
You also need to include pdfbox-1.6.0 and commons-logging in your app.
Read the PDF into a Stream then copy into a MemoryStream to allow seeking. To pass the Stream into PdfBox, it has to be a java.io.InputStream, so it is converted via a byte array. Then it is simply loaded into a PDDocument and the PDFTextStripper can return a string of all the text in the document.

Downloads
If you want to try this on your own, here are links to everything we used.
- AzureDirectory allows Lucene to use blob storage instead of a standard file system. https://code.msdn.microsoft.com/AzureDirectory
- Lucene does the actual indexing and searching. https://incubator.apache.org/lucene.net/download.html
- PdfBox is the best PDF parser I could find, even though it is written in Java.
- Java version – https://pdfbox.apache.org/download.html
- .NET version – https://pdfbox.lehmi.de/
- IKVM lets us use PdfBox in a .NET application by recompiling Java code into DLLs. https://sourceforge.net/projects/ikvm/files/